
Web Scraping con R
¿Qué es web scraping?
El Web Scraping (rascado en español) es una técnica que se usa para la extracción de datos no estructurados de una página web, los cuáles podemos analizar o manipular posteriormente.
En ocasiones interesa descargar cierta información directamente de una o varias páginas de un sitio web, aunque esta no se encuentre fácilmente accesible.
Las posibles usos del web scraping son muy variados y, aunque el ejemplo que vamos a incluir más abajo, vamos a realizar una extracción de información puramente SEO, para saber qué listados de información publica la competencia, existen otros muchos usos: clasificación de productos/servicios para creación de motores de recomendación, obtención de datos para creación de sistemas basados en procesamiento de lenguajes naturales, obtención de las etiquetas de imágenes para la clasificación de contenido gráfico, obtención de datos de redes sociales para análisis de sentimientos…
¿Por qué usar R?
Aunque para el web scraping existen complementos o software especializado, nosotros nos decantamos por usar el lenguaje de programación R (aunque no es el único lenguaje) y sus librerías. Esto nos permite programar un algoritmo a medida, lo que nos da mucha más flexibilidad: programar extracciones con cierta frecuencia, gestionar errores o adaptarnos a los cambios de la web de origen con mayor flexibilidad. Este es el mejor método para realizar web scraping complejos, con un gran volumen de datos y frecuentes.
Ejemplo práctico: ¿Cómo realizar la extracción de los tratamientos médicos que incluye cun.es?
Este caso, el acceso a las diferentes páginas del listado se genera mediante AJAX. En estos casos, necesitaríamos una solución que incorpore un motor de Javascript.
Para hacer scraping con R, necesitamos dos cosas básicamente:
- Tener instalado R y seguir los pasos que se incluyen a continuación.
- Tener conocimientos básicos de HTML y CSS.
Para hacer web scraping con R debemos hacer uso del paquete “Rvest”. Esta librería básicamente permite extraer datos de una página usando HTML y XML. Podemos instalarla escribiendo en la consola lo siguiente:
install.packages(“rvest”)
A continuación tecleamos:
library(“rvest”)
Para saber cómo funciona con más detalle podemos acceder a la siguiente dirección: https://cran.r-project.org/web/packages/rvest/rvest.pdf
Para nuestro ejemplo, basta con saber que unos de lo métodos que se incluyen en la librería es read_html(“url”). Esta función permite crear un objeto que contiene todas las etiquetas HTML.
Para crear el objeto escribimos en consola:
html.cun <- read_html(“https://www.cun.es/enfermedades-tratamientos/tratamientos”)
Cuando tenemos todas las etiquetas HTML, podemos acceder a cualquiera de sus nodos, que no son otra cosa que párrafos, imágenes, enlaces, tablas…
Aunque las necesidades de obtener datos dependen de cada proyecto, en este caso, por simplificar, se extraerán todos los tratamientos que incluye la web de CUN.
Para ello, debemos identificar el nodo es cuestión haciendo uso de XPath o CSS Selector. Con Chrome es muy fácil hacer esto ya que podemos inspeccionar un elemento en la consola y copiar el XPath:
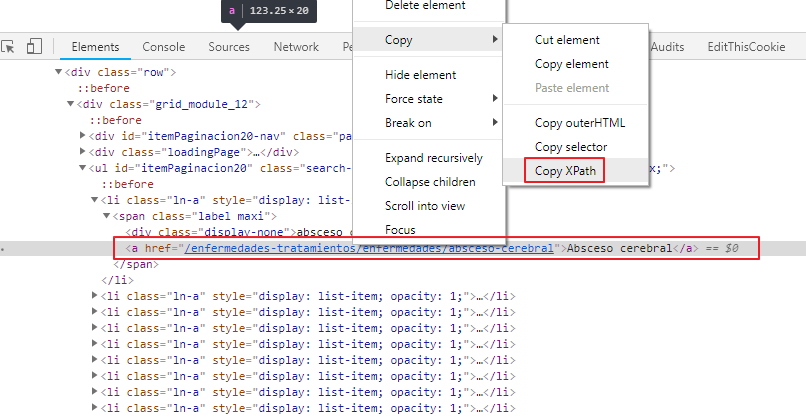
Una vez que hemos copiado el XPath, lo que demos es llamar a las funciones html_nodes() y html_text() de la siguiente forma para extraer los datos:
tratamientos <- html.definicion.temp %>% html_nodes(xpath = ‘//div[contains(@id,”main”)]’) %>% html_text()
Con html_nodes() obtendríamos un listado de los div cuyo id es “main” y con html_text() extraeríamos únicamente el texto, que es lo que almacenaríamos en la variable “tratamientos”.
De esta forma, estaríamos obteniendo todos los tratamientos que se incluyen en la página en cuestión.
Una vez obtenida información, ya podemos usarla para fines SEO y para realizar cualquier tipo de análisis.





