El muro de Google: Experimentos JavaScript 2020
¡Hola, comunidad!
Recientemente participé como SEO Manager de Internet República en ClickSEO 2020, un evento online y gratuito que tuvo lugar el 7 y 8 de diciembre con la intervención de numerosos expertos en SEO, y en el que también participó mi compañera Marta Romera, SEO Manager en Internet República.
En mi charla en ClickSEo hablé de unos experimentos que hemos hecho con SEO y JavaScript en 2020, y que os quiero contar aquí.
Aunque en este post os explico cuáles eran estos experimentos, podéis ver el vídeo de la charla completa aquí.
Google anunció a mediados de 2019 Google Evergreen, y queríamos hacer unos experimentos JavaScript para comprobar qué diferencia había con otros que hicimos en 2019, y si realmente ha habido cambios o no.
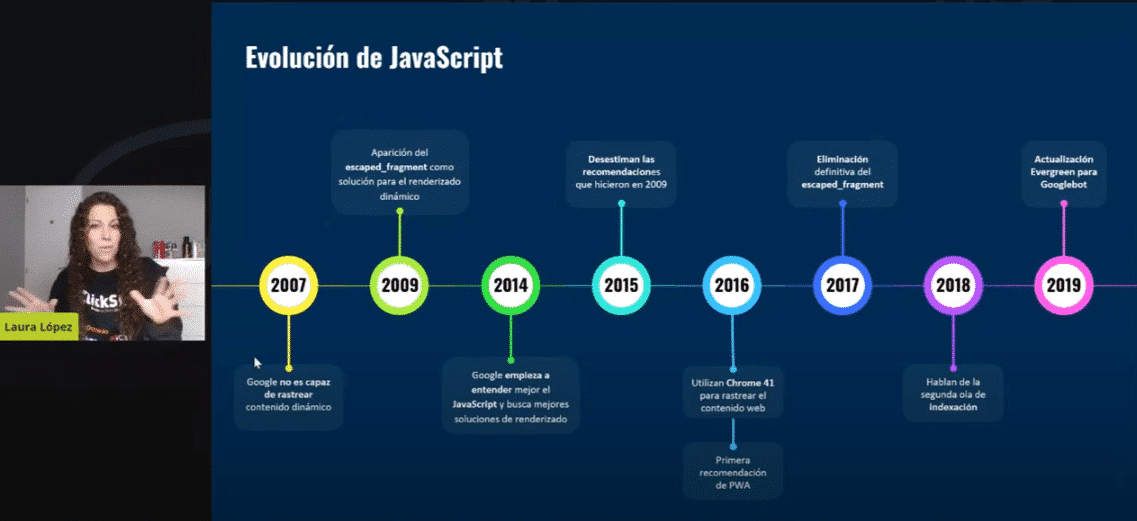
Para empezar y ponernos un poco en contexto, como sabéis el SEO en JavaScript ha tenido una evolución durante los últimos años bastante llamativa. Pensad que alrededor de 2009 Google no era capaz de procesar páginas en JavaScript, de hecho lo que anunciaron y lo que recomendaban en esa época era que incluyésemos un argumento en la URL que se llamaba “escaped fragment”, para que pudiesen entender cuáles son las páginas que tenían un cambio de contenido dinámico, y de esa forma pudiesen identificarlas y procesarlas, porque de forma natural Google no era capaz de interpretar cuándo una página cambiaba dinámicamente, al no poder procesar JavaScript.
En la conferencia anual de 2018 ya anunciaron cómo procesaban JavaScript, pero no es hasta 2019 cuando Google empieza a utilizar Evergreen, la última versión de Chrome vigente para procesar y renderizar este contenido en JavaScript. Esto iba a ser la revolución, Google iba a procesar de forma activa y a mejorar muchísimo. Ahora veremos si realmente ha sido así.
En grandes agencias como Internet República cada vez que llega un cliente nuevo y preguntas en qué tecnología se va a desarrollar la web nueva o los cambios que se van a hacer, todo el mundo quiere hacer las páginas nuevas en JavaScript, por un tema de dinamismo, para mejorar la usabilidad del usuario y hacer ese contenido más dinámico.
El desarrollo de páginas web en este tipo de tecnologías está creciendo de manera brutal. Pero no todo es tan bonito, ni tan funcional.
¿Qué problemas tenemos con SEO y JavaScript?
El principal problema es que el proceso que sigue Google para rastrear este contenido es que Googlebot descarga ese fichero html, digamos la parte básica, y a partir de ahí es cuando el contenido encuentra JavaScript, ya sea de recursos que tiene en JavaScript, funcionalidades o CSS, lo que hace es que lo identifica y lo procesa. Procesa esa página html con estos recursos CSS JavaScript, los revisa, los compila y los ejecuta. Eso pasa a la parte del renderizador de Google e indexa ese contenido.
Este proceso es más complejo, compilar y ejecutar ese JavaScript llevan muchísimo más tiempo que procesar una página en html tradicional. Por lo tanto, ahí ya vamos a tener un problema de tiempo a la hora de procesar nuestras páginas con contenido JavaScript.
Y es que Google indexa lo que renderiza, es decir, si hay parte que no le ha dado tiempo a renderizar o que no ha renderizado no lo va a indexar. Por lo tanto, es muy importante que nos aseguremos que, lo que tenemos en JavaScript, Google lo renderiza y lo indexa de forma completa. Porque al rastrear contenido en JavaScript, se supone que esos enlaces los procesa, los ejecuta y los indexa, pero hay veces que esto no ocurre, y hay enlaces que se quedan sin procesar.
Por otro lado, también nos encontramos con la problemática de que en las páginas normales tenemos el crawl budget limitado, por lo tanto todo este tiempo que se tarda en procesar, también nos perjudica a la hora de trabajar otras páginas en JavaScript.
En la actualidad, ¿cómo se está haciendo ahora?, o ¿cómo dice Google que está sucediendo cuando anuncia este cambio a Evergreen?. Es decir, cuando anuncian que ya van a procesar todo se JavaScript con la última versión de Chrome vigente, ¿qué supone?
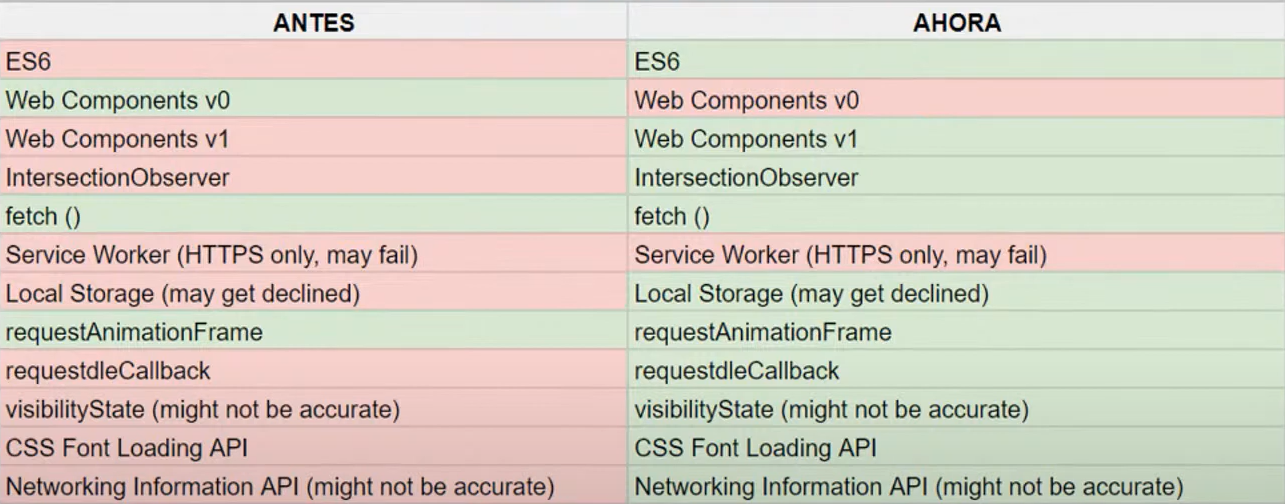
Este cuadro muestra algunas de las funcionalidades JavaScript (en rojo) que antiguamente no eran capaces de procesar, y que ahora con Evergreen sí que son capaces de procesar. Así que, si tienes una página con muchas funcionalidades en JavaScript en las cuales tenías funcionalidades como las que se marcan en rojo, que Google antes no era capaz de procesar, evidentemente tu contenido se procesará mejor ahora que antes.
¿Qué experimentos hemos hecho?
Con los experimentos, hemos querido comprobar si esto supone algún cambio. Con estos experimentos vamos a mostrar cómo el usuario ve el contenido de una página web en JavaScript y cómo la ve Google. Y las principales diferencias son estas:
- Googlebot no descarga todos los recursos que existen en una página. Por lo tanto, un usuario entra en una página en JavaScript y ve todo el contenido, pero Google hay veces que no procesa todos esos recursos, hay parte de ese contenido que puede que no vea. Con toda la personalización que estamos teniendo ahora en webs y con estas tecnologías JavaScript que hacen contenido dinámico, y que a veces utilizan esta personalización, tenemos que tener en cuenta que para Google esto es invisible, porque no utiliza cookies.
- Google solo renderiza 5 segundos, esto lo vamos a comprobar en los experimentos, pero yo quería comprobar si realmente en 2020, con Evergreen, ha cambiado algo o seguimos con los 5 segundos de renderizado .
- Otra de las cosas que se sabe y que se ha comprobado es que Google no interactúa con ciertos recursos, pero esto hemos querido comprobarlo también.
Experimentos que hicimos en 2019
Definimos una serie de experimentos durante 2019 antes de Evergreen, para que luego veáis la diferencia con lo que tenemos ahora en 2020.
Lo primero que hicimos el año pasado fue generar una página con un producto con scroll que se carga directamente cuando entras a la página, pero productos 2, 3, y todos los sucesivos se cargan solo cuando haces scroll. Por lo tanto, dijimos: “vamos a ver si Google es capaz de indexar el contenido de producto 2 y producto 3. El producto 1, que no lleva un scroll sí que directamente se pintaba en la página, lo indexa perfectamente, pero en 2019 Google no era capaz de hacer scroll y no indexaba el contenido que yo tenía montado debajo de un scroll por JavaScript.
El segundo experimento que hicimos fue montar una página con un botón de cargar más en JavaScript. Muchas páginas de e-commerce tienen un botón de “ver más” con un evento JavaScript, y cuando interactúas con el botón, carga el resto del contenido. Hicimos la prueba y vimos que Google no interactúa con este botón JavaScript, o por lo menos no lo hacía cuando hicimos los experimentos en 2019.
El tercer experimento que hicimos fue hacer una carga secuencial, cargando partes del código cada segundo para comprobar hasta cuánto tiempo Google nos indexaba esta parte del código, de forma que nos pudiese dar la captura de cuánto era el segundo máximo que Google obtenía para la indexación de la página. Confirmamos que, efectivamente, son 5 segundos los que Google utiliza para procesar e indexar ese contenido.
También capturamos las cookies para ver si realmente las tenía habilitadas, y sí las tiene, pero no persisten entre peticiones. Es decir, realmente no puede utilizar el contenido con cookies.
¿Qué ha cambiado en 2020?
Este año, hemos querido comprobar si ha cambiado algo con Evergreen. Lo que hicimos fue lo mismo, comprobar si bajo el scroll nos indexaba el contenido. El resultado es que el producto uno sí lo carga, pero si hacemos scroll no coge nada.
También quisimos comprobar si Evergreen, con las nuevas funcionalidades, capta la interacción en botones JavaScript. Pero, efectivamente, al igual que el año pasado, no interactúa.
Finalmente, quisimos comprobar si con Evergreen habían mejorado esos 5 segundos de renderizado que teníamos el año pasado. Y como hemos visto en Google Evergreen, el renderizado es de 5 segundos a efectos prácticos. Por lo tanto, de eso es lo que nos tenemos que asegurar, que nuestra página JavaScript cargue correctamente en 5 segundos.
Por tanto, los experimentos del año pasado y los de este son exactamente iguales. En resumen, de los experimentos que hemos hecho todos han sido igual, excepto las versiones de Chrome diferentes entre las del año pasado y las de este, que sí que son más actuales.
Pero sigue sin detectar el scroll y sin hacer la carga del botón ver más, el renderizado y la indexación son 5 segundos, y las cookies están habilitadas aunque no persisten entre peticiones y no las tiene en cuenta.
Conclusión, a efectos prácticos estamos igual que el año pasado, así que para mí la conclusión es que todo sigue igual, que Evergreen no ha cambiado nada, que la indexación sigue funcionando de la misma manera, y que vamos a tener que seguir haciendo el mismo SEO para JavaScript que el que llevamos haciendo desde 2019.




Nací en Málaga y dicen que seseo.

