
Extraer contenido específico con Screaming Frog
Para extraer contenido específico de una URL o de un site entero, Screaming Frog es una de las mejores opciones. Es una de las principales herramientas a la hora obtener cualquier tipo
de información On Page: titles, descriptions, h1, canonical, status, redirecciones, etc.
Es muchísima la información útil que puede aportar esta herramienta, pero, ¿queremos más?

Sí, queremos más.
Custom extract
Screaming Frog puede extraer información específica a través del módulo “Custom Extraction” (Configuration > Custom > Extraction) y algo de sintaxis en XPath.
En el panel que nos muestra, podemos elegir las opciones de desplegable. Por un lado, el método de extracción, y por otro lado, lo que se va a extraer. XPath es un lenguaje que permite recorrer el documento HTML en busca de elementos específicos para seleccionarlos y, en este caso rastrear su contenido de texto, elementos anidados o contenido HTML.
¿Y qué podemos extraer? De entre las opciones que encontramos en el segundo desplegable de opciones encontramos:
- Extract HTML Element: Extraerá el elemento seleccionado y su contenido.
- Extract Inner HTML: Elementos HTML y su contenido interno, incluidas etiquetas anidadas en dicho elemento
- Extract Text: Contenido de texto del elemento seleccionado, así como el contenido de las etiquetas anidadas en dicho elemento (si las hay)
¿Cómo extraer contenido específico?
Veamos algunos ejemplos de cómo extraer el contenido que nos interesa con Screaming Frog.
A la hora de seleccionar una etiqueta, y seleccionar todas las que existan en una URL, XPath utiliza dos barras seguidas del tipo de etiqueta que queremos extraer.
Por ejemplo, si queremos extraer los titulares h3 de un documento, escribiremos: //h3
Ahora bien, puede que encontremos muchos titulares h3 en la página y sólo nos interesen los que cuentan con una clase específica. XPath permite seleccionar un elemento y también sus atributos (una clase, id, alt de imagen, URL de destino de un href o src, etc.). Para seleccionar los atributos de un elemento, primero hay que seleccionar el elemento, y después sus atributos entre corchetes de la siguiente manera:
//elementoHTML[@nombreAtributo='valorDelAtributo']
Por ejemplo, si necesitamos extraer sólo los titulares h3, que cuenten con la clase “h3-rojo”, lo podemos hacer de la siguiente manera:
//h3[@class='h3-rojo']
También podemos seleccionar sólo los h3 con la clase “h3-rojo” que estén incluidos en una sección específica, un div con una clase específica de la siguiente manera:
//elementoPadre[@atributo='valor']//elementoHijo[@atributo='valor']
¿Qué tal extraer sólo los h3 rojos incluidos en una etiqueta <div> con un atributo id=”contenido-principal”?
//div[@id='contenido-principal']//h3[@class='h3-rojo']
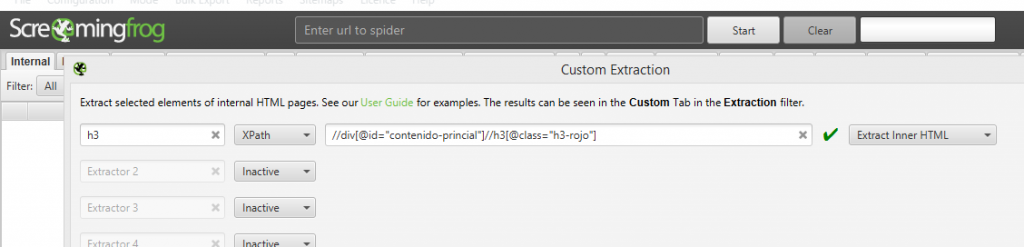
¿Y cuál es la manera más sencilla de hacer todo esto? Tener una base de cómo funciona XPath está muy bien, pero el inspector de código del navegador puede escribir la expresión que necesitamos fácilmente:
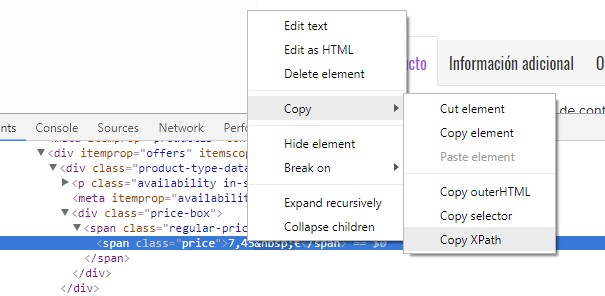
Una vez seleccionado el elemento, sólo nos queda añadir el dominio o la lista de URL a rastrear. Pinchar “Start”. En la pestaña “Directives” encontraremos nuestro contenido. ¡Magia!




